Stoploss
Hospital Data
Use additional_generic_notes and additional_payer_notes from hospital data to identify stoploss-related terms.
Step 1: Exclude Noise in Text Fields
There are 16M distinct pairs of (additional_generic_notes, additional_payer_notes) in the hospital data.
The following filters remove ~15 million pairs that definitely do not contribute meaningful stoploss information.
| # | Description | Regex Condition | Pairs Removed |
|---|---|---|---|
| 1 | Notes that mention Hospital System Supply Identifier and end with Lawson ID, with no payer notes | REGEXP_LIKE(additional_generic_notes, 'Hospital System Supply Identifier.*Lawson ID$') AND additional_payer_notes IS NULL | 12,675,893 |
| 2 | Notes ending in "Term Line "number"", with no payer notes | REGEXP_LIKE(additional_generic_notes, 'Term Line \\d+$') AND additional_payer_notes IS NULL | 1,194,161 |
| 3 | Notes that say: "The contract rate provided is when this service is billed outpatient.", with no payer notes | REGEXP_LIKE(additional_generic_notes, 'The contract rate provided is when this service is billed outpatient.') AND additional_payer_notes IS NULL | 616,115 |
| 4 | Notes that start with "Re-evaluated:", with no payer notes | REGEXP_LIKE(additional_generic_notes, '^Re-evaluated: ') AND additional_payer_notes IS NULL | 340,510 |
| 5 | Payer notes that start with "contract indicates payment" | REGEXP_LIKE(additional_payer_notes, '^contract indicates payment') | 127,958 |
| 6 | Notes that are just a number, and payer notes say something like "xx% of charges" | REGEXP_LIKE(additional_generic_notes, '^\\d+$') AND REGEXP_LIKE(UPPER(additional_payer_notes), '^\\d+% OF TOTAL BILLED CHARGES$|^\\d+% TOTAL BILLED CHARGES$|^\\d+% OF CHARGES$') | 35,289 |
| 7 | Notes formatted like "Rev "number" Proc "number"", with no payer notes | REGEXP_LIKE(additional_generic_notes, 'Rev \\d+ Proc \\d+') AND additional_payer_notes IS NULL | 423,532 |
| 8 | Pairs where neither field contains a number | REGEXP_LIKE(additional_generic_notes, '\\d') OR REGEXP_LIKE(additional_payer_notes, '\\d')(negated) | 159,033 |
We then filter down to additional_generic_notes and additional_payer_notes that contain at least one of the following terms:
- stop
- loss
- threshold
- discount
- charges
- outlier
Step 2: Extract Highest Numeric Values from Text Fields
Use this python function to extract the highest numeric value from each field:
def extract_highest_number(text):
if not text:
return None
pattern = r'\$?\s*(\d+(?:,\d{3})*(?:\.\d+)?|\d+(?:\.\d+)?)([kK]?)'
matches = re.findall(pattern, text)
values = []
for num_str, k_flag in matches:
try:
num = float(num_str.replace(',', ''))
if k_flag.lower() == 'k':
num *= 1000
values.append(num)
except ValueError:
continue
return max(values) if values else None
Then filter to rows where either extracted value is between $50,000 and $6 million.
df_filtered = df.loc[
((df['highest_number_generic'] > 50_000) & (df['highest_number_generic'] < 30e6))
| ((df['highest_number_payer'] > 50_000) & (df['highest_number_payer'] < 30e6))
].copy()
Step 3: Save Results:
Results are saved to tq_dev.internal_dev_csong_sandbox.clear_rates_hospital_data_stoploss table.
SELECT *
FROM tq_dev.internal_dev_csong_sandbox.clear_rates_hospital_data_stoploss
ORDER BY RANDOM()
LIMIT 100
| payer_id | provider_id | additional_generic_notes | additional_payer_notes | plan_names | highest_number_generic | highest_number_payer |
|---|---|---|---|---|---|---|
| 636 | 6000 | Stop-loss discount of 42.4000 percent applies when charges exceed 107826.97 | ['SELECTVALUE', 'SELECTSHARE', 'FEHBP'] | nan | 107827 | |
| 1184 | 6012 | Stop-loss discount of 55.6000 percent applies when charges exceed 60724.22 | ['SELECT'] | nan | 60724.2 | |
| 1184 | 5992 | Stop-loss discount of 87.3000 percent applies when charges exceed 96954.96 | ['SELECT', 'ALL OTHER'] | nan | 96955 | |
| 61 | 5981 | Stop-loss discount of 76.0000 percent applies when charges exceed 60520.51 | ['TRADITIONAL'] | nan | 60520.5 | |
| 12 | 6000 | Stop-loss discount of 48.2000 percent applies when charges exceed 173310.72 | ['MED NETWORK'] | nan | 173311 | |
| 12 | 6028 | Stop-loss discount of 48.2000 percent applies when charges exceed 159715.16 | ['MED NETWORK'] | nan | 159715 | |
| 98 | 5992 | Stop-loss discount of 87.3000 percent applies when charges exceed 71059.26 | ['COMMERCIAL'] | nan | 71059.3 | |
| 1184 | 5992 | Stop-loss discount of 87.3000 percent applies when charges exceed 72582.14 | ['SELECT', 'ALL OTHER'] | nan | 72582.1 | |
| 7 | 1641 | If billable gross charges exceed threshold of $50397.25, charges over the threshold will be paid at 45.52% of billable gross charges in addition to the contracteded rate. | ['AETNAPREFERRED'] | nan | 50397.2 | |
| 643 | 457 | Days 3+. If billable gross charges exceed threshold of 4451 per diem instead of the contracted rate. | ['SMALLGROUP'] | nan | 632883 |
Claims (Komodo)
Filter Komodo medical_headers to Commercial plans, inpatient claims, with
patient DOB >= 1960, and total claim charge amount > $5000 or total line charge
> $5000 (well below stoploss thresholds). Then join in total allowed amounts.
Store in tq_dev.internal_dev_csong_sandbox.komodo_high_allowed_amount_encounters
View SQL Query to Setup Analysis
CREATE TABLE tq_dev.internal_dev_csong_sandbox.komodo_high_allowed_amount_encounters AS
WITH
provider_spine AS (
SELECT
DISTINCT
provider_id,
provider_name,
npi_value AS npi
FROM
tq_dev.internal_dev_csong_cld_v2_0_0.prod_rollup_provider,
UNNEST(npi) AS t(npi_value)
WHERE
provider_id IS NOT NULL
AND provider_type LIKE '%Hospital%'
),
high_allowables AS (
SELECT encounter_key, sum(allowed_amount) AS total_allowed_amount
FROM tq_intermediate.external_komodo.allowed_amounts
GROUP BY encounter_key
HAVING sum(allowed_amount) > 1000
),
remit_totals AS (
SELECT
encounter_key,
sum(allowed_amount) AS remit_allowed_amount,
sum(paid_amount) AS remit_paid_amount
FROM tq_intermediate.external_komodo.remits
GROUP BY encounter_key
HAVING sum(allowed_amount) > 1000
OR sum(paid_amount) > 1000
),
charge_totals AS (
SELECT encounter_key, sum(line_charge) AS total_line_charge
FROM tq_intermediate.external_komodo.medical_service_lines
GROUP BY encounter_key
HAVING sum(line_charge) > 5000
)
SELECT
mh.encounter_key,
ps.provider_id,
ps.provider_name,
mh.hco_1_npi,
mh.kh_plan_id,
mp.payer_id,
mp.payer_name,
mp.insurance_group,
mh.total_claim_charge_amount,
msl.total_line_charge,
ha.total_allowed_amount,
rm.remit_allowed_amount,
rm.remit_paid_amount
FROM tq_intermediate.external_komodo.medical_headers mh
JOIN tq_intermediate.external_komodo.plans mp
ON mh.kh_plan_id = mp.kh_plan_id
JOIN provider_spine ps
ON mh.hco_1_npi = ps.npi
LEFT JOIN high_allowables ha
ON mh.encounter_key = ha.encounter_key
LEFT JOIN remit_totals rm
ON mh.encounter_key = rm.encounter_key
LEFT JOIN charge_totals msl
ON mh.encounter_key = msl.encounter_key
WHERE
mh.claim_type_code = 'I'
AND mh.bill_type_code = '111'
AND YEAR(mh.patient_dob) >= 1960
AND mp.insurance_group = 'COMMERCIAL'
AND (
mh.total_claim_charge_amount > 5000
OR
msl.total_line_charge > 5000
)
AND (ha.encounter_key IS NOT NULL OR rm.encounter_key IS NOT NULL)
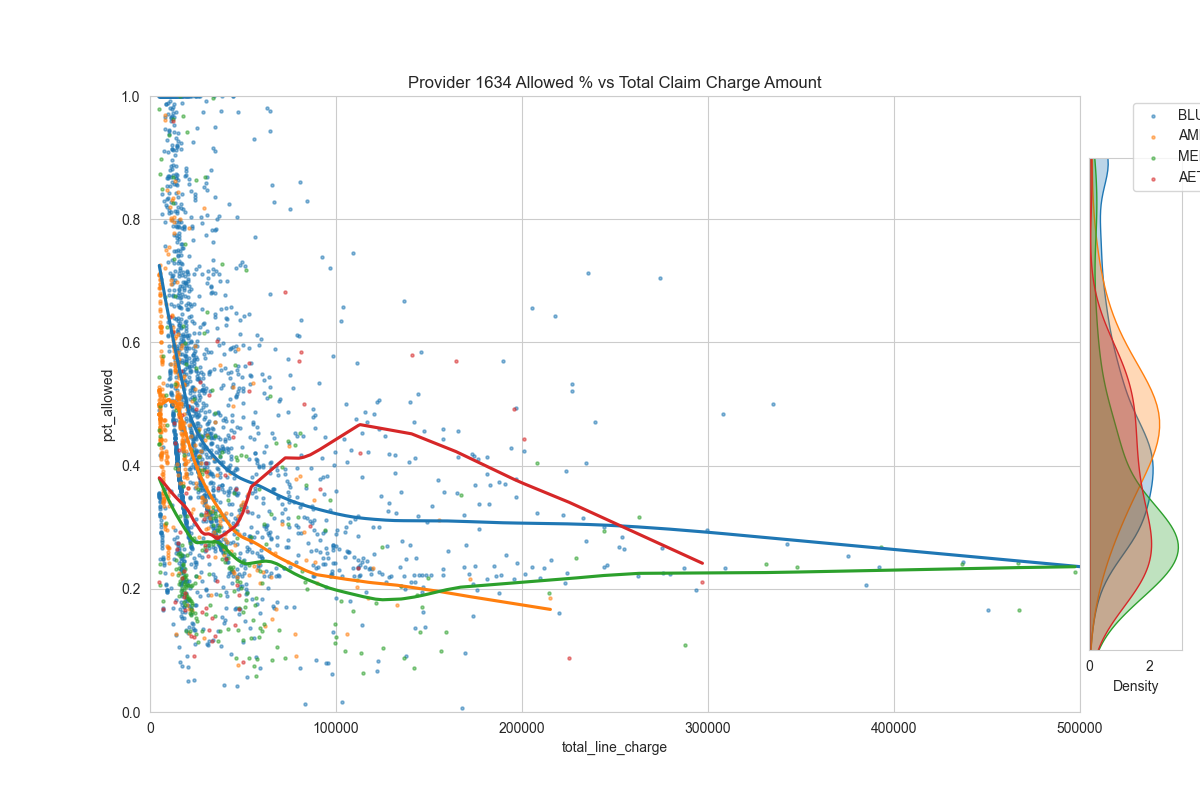
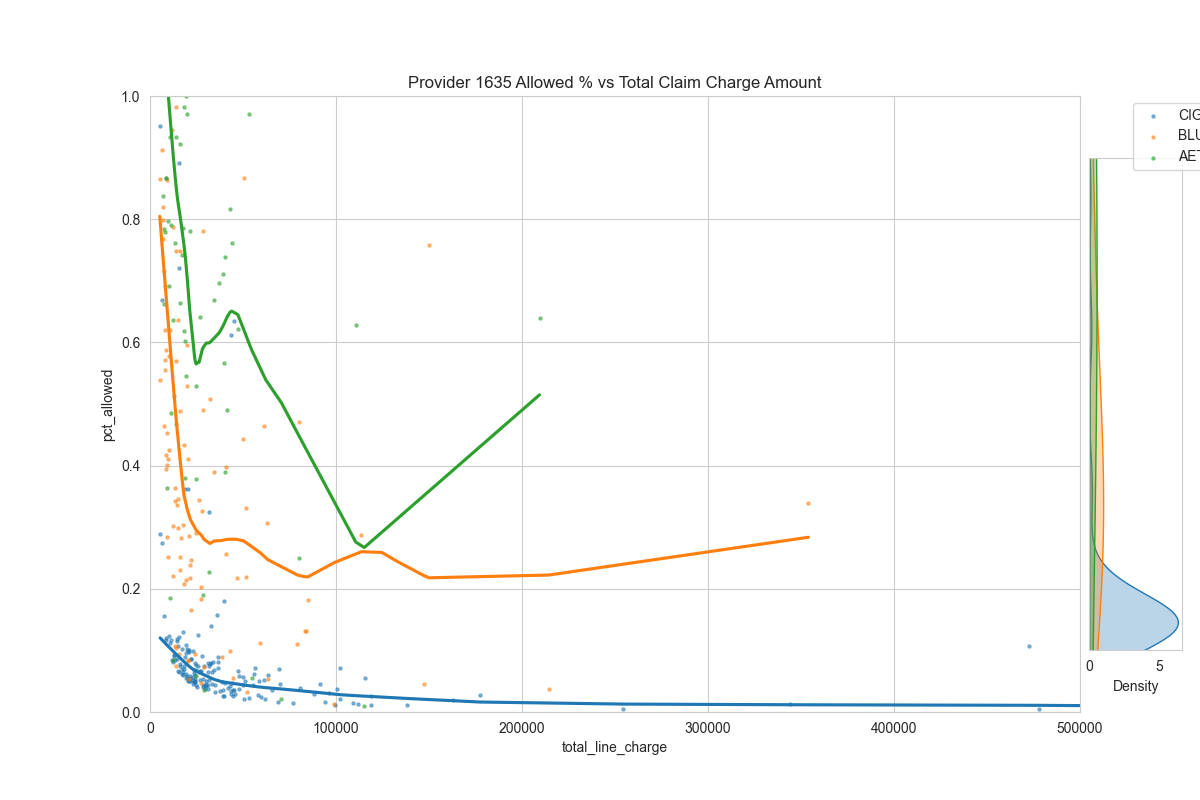
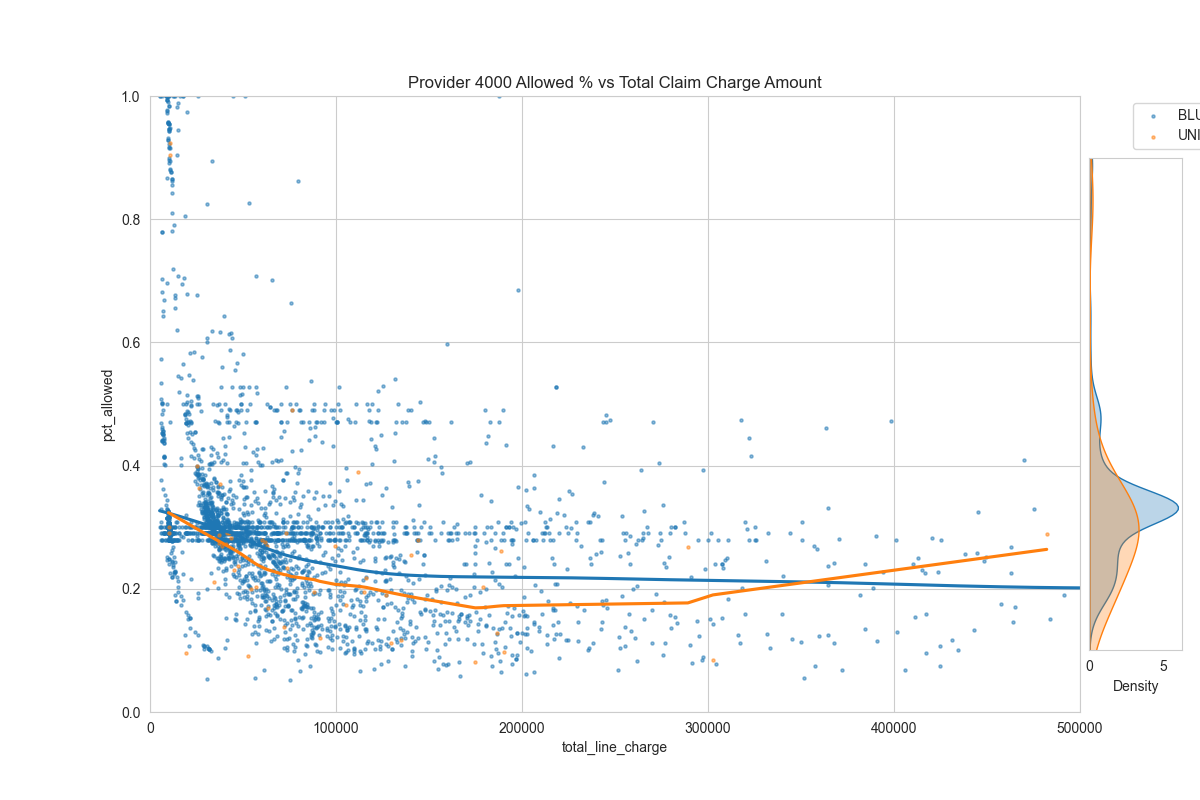
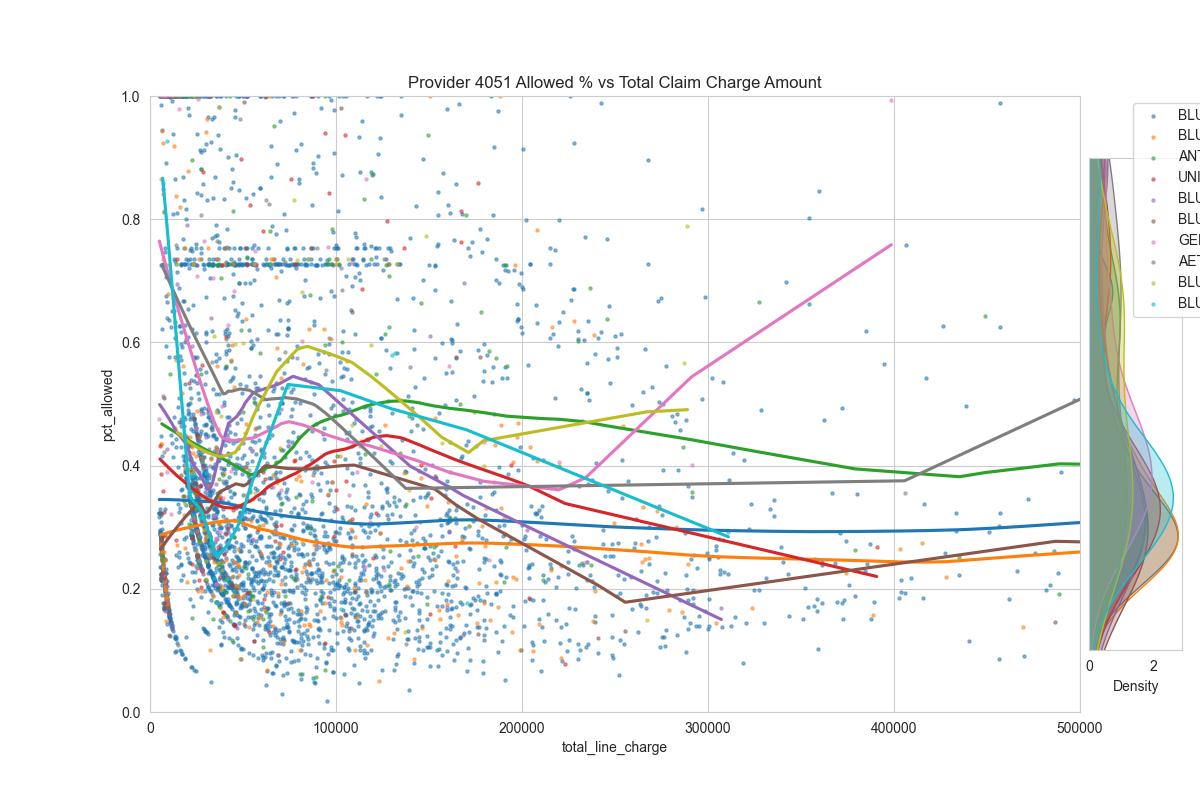
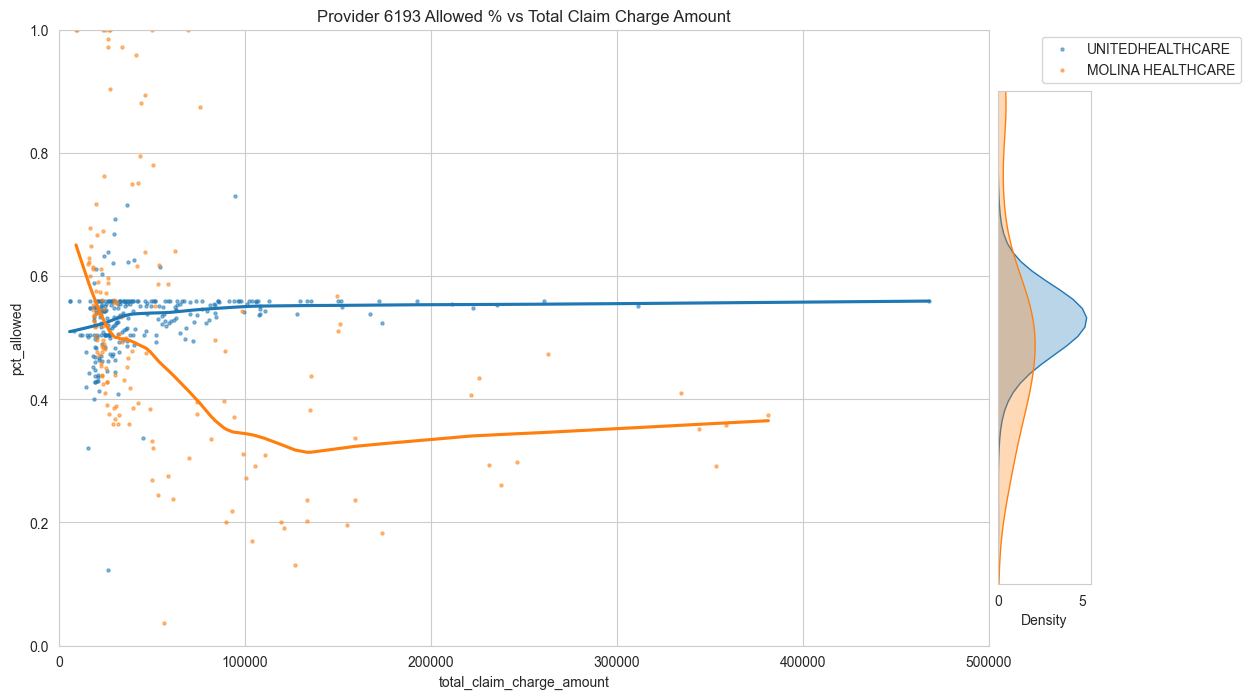
Then, we can compute the % of charge of each encounter. Then plot the % of charge (y-axis) against the total charge amount (x-axis) to look for stoploss patterns.
View Python to Create Viz
df = pd.read_sql(f"""
WITH
sample AS (
SELECT provider_id, COUNT(*) AS cnt
FROM tq_dev.internal_dev_csong_sandbox.komodo_high_allowed_amount_encounters
WHERE provider_id IN (
SELECT DISTINCT provider_id
FROM tq_dev.internal_dev_csong_sandbox.clear_rates_hospital_data_stoploss s
)
GROUP BY provider_id
HAVING COUNT(*) > 500
ORDER BY RANDOM()
LIMIT 1
)
SELECT *
FROM tq_dev.internal_dev_csong_sandbox.komodo_high_allowed_amount_encounters
WHERE provider_id IN (SELECT provider_id FROM sample)
""", con=trino_conn)
df_sample = df.loc[
(df['total_line_charge'] < 1_000_000)
].copy()
df_sample['pct_allowed'] = df_sample['total_allowed_amount'] / df_sample['total_line_charge']
sns.set_style("whitegrid")
payer_counts = df_sample['payer_name'].value_counts()
selected_payers = payer_counts[payer_counts > 40].index
fig = plt.figure(figsize=(12, 8))
main_ax = plt.gca()
# Plot main regplots
for payer_name in selected_payers:
df_payer = df_sample[df_sample['payer_name'] == payer_name]
sns.regplot(
data=df_payer,
y="pct_allowed",
x="total_line_charge",
label=payer_name,
lowess=True,
scatter_kws={"s": 5, "alpha": 0.5},
ax=main_ax
)
main_ax.set_ylim(0, 1)
main_ax.set_xlim(0, 500_000)
handles, labels = main_ax.get_legend_handles_labels()
new_labels = [label for label in labels if label not in ['size', '2']]
new_handles = handles[:len(new_labels)]
main_ax.legend(new_handles, new_labels, bbox_to_anchor=(1.05, 1), loc='upper left')
main_ax.set_title(f"Provider {df_sample['provider_id'].values[0]} Allowed % vs Total Claim Charge Amount")
# Add inset axis for horizontally-oriented KDEs on right margin
kde_ax = main_ax.inset_axes([1.01, 0.1, 0.1, 0.8], sharey=main_ax)
for payer_name in selected_payers:
df_payer = df_sample[df_sample['payer_name'] == payer_name]
sns.kdeplot(
y=df_payer["pct_allowed"],
ax=kde_ax,
label=payer_name,
fill=True,
alpha=0.3
)
kde_ax.grid(False)
kde_ax.get_yaxis().set_visible(False)
plt.show()
Examples:
It's very noisy. But perhaps there's something here...