Scores
Canonical Rate Scores
Each rate is assigned a validation score in the pipeline, which are mapped to
a 1-5 canonical_rate_score at the end of the pipeline.
| Canonical Rate Score | Interpretation | Validation Scores (Raw/Transform) | Validation Scores (Imputed) |
|---|---|---|---|
| 5 | Validated | 7 | N/A |
| 4 | Raw - Payer/Hospital Posted Dollar; Not Outlier | 6.XX | 3.XX |
| 3 | Transform/Impute - Medicare Benchmark Validated | 5.XX | 2.XX |
| 2 | Transform/Impute - Not Medicare Validated but not an outlier | 4.XX | 1.XX |
| 1 | Outlier | 0 | 0 |
| 0 | Rate Does Not Exist | -1 | -1 |
Flow Chart
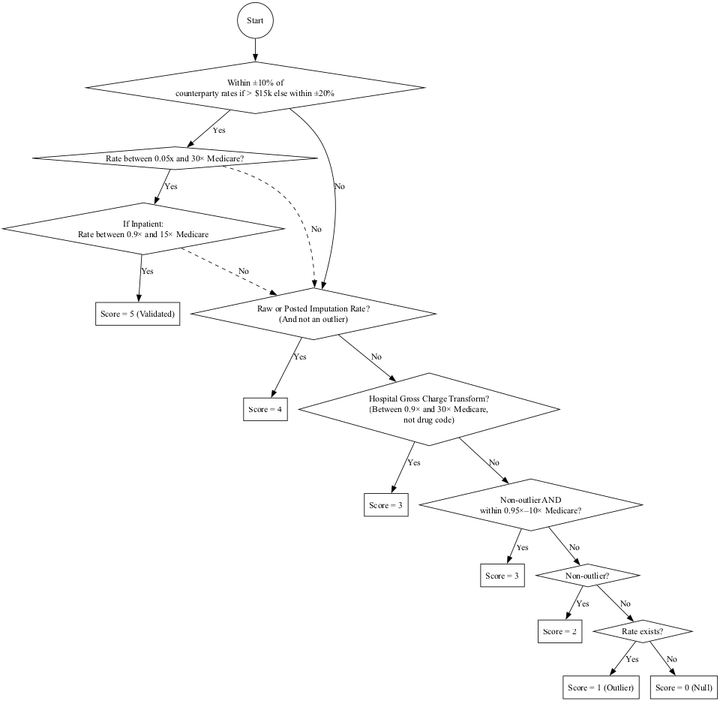
Code
from graphviz import Digraph
# Initialize directed graph
dot = Digraph(comment="Accuracy Score Flow (Gross Charge 0.9x–100x Medicare)", format="png")
dot.attr(rankdir="TB", size="10")
# Start
dot.node("A", "Start", shape="circle")
# ±20% check first
dot.node("D", "Within ±20% of\ncounterparty rates?", shape="diamond")
dot.edge("A", "D")
# Global Medicare bound <100x
dot.node("D2", "Rate < 100× Medicare?", shape="diamond")
dot.edge("D", "D2", label="Yes")
# Medicare bound checks after ±20%
dot.node("D3", "If Inpatient:\nRate between 0.9× and 100× Medicare", shape="diamond")
dot.edge("D2", "D3", label="Yes")
# Score 5 validated if holds
dot.node("S5v", "Score = 5 (Validated)", shape="box")
dot.edge("D3", "S5v", label="Yes")
# Fallthroughs if checks fail
dot.edge("D", "F", label="No")
dot.edge("D2", "F", label="No", style="dashed")
dot.edge("D3", "F", label="No", style="dashed")
# Raw/post imputation
dot.node("F", "Raw or Posted Imputation Rate?\n(And not an outlier)", shape="diamond")
dot.node("S4r", "Score = 4", shape="box")
dot.edge("F", "S4r", label="Yes")
# Gross charge transform (edited to 0.9x–100x Medicare)
dot.node("G", "Hospital Gross Charge Transform?\n(Between 0.9× and 100× Medicare,\nnot drug code)", shape="diamond")
dot.edge("F", "G", label="No")
dot.node("S3t", "Score = 3", shape="box")
dot.edge("G", "S3t", label="Yes")
# Medicare benchmark
dot.node("H", "Non-outlier AND\nwithin 0.95×–10× Medicare?", shape="diamond")
dot.edge("G", "H", label="No")
dot.node("S3b", "Score = 3", shape="box")
dot.edge("H", "S3b", label="Yes")
# Non-outlier generic
dot.node("I", "Non-outlier?", shape="diamond")
dot.edge("H", "I", label="No")
dot.node("S2n", "Score = 2", shape="box")
dot.edge("I", "S2n", label="Yes")
# Outlier case
dot.node("J", "Rate exists?", shape="diamond")
dot.edge("I", "J", label="No")
dot.node("S1o", "Score = 1 (Outlier)", shape="box")
dot.edge("J", "S1o", label="Yes")
# Score 0 (null)
dot.node("S0", "Score = 0 (Null)", shape="box")
dot.edge("J", "S0", label="No")
# Render PNG
output_path = "/mnt/data/accuracy_score_flow_grosscharge_0.9x_100x"
dot.render(output_path, format="png", cleanup=False)
output_path + ".png"
Validation Definitions
| Method | Criteria |
|---|---|
| Medicare Validated - Medical | Between 0.95x and 10x of Medicare; Exception: if the rate type is a percent to dollar transformation using a hospital MRF gross charge, rate must be between 0.9x and 100x the Medicare rate |
| Medicare Validated - Drugs | Between 0.80x and 4x for Hospital rates; Between 0.80x and 10x for payer rates |
| Outlier - Medical | Between Q1 - 2\*IQR and Q3 + 2\*IQR; (Note that these boundaries are computed on the log scale); Exception: IP lower bound is always 90% of Medicare |
| Outlier - Drugs | Same as "Medicare Validated - Drugs": Between 0.80x and 4x for Hospital rates; Between 0.80x and 10x for payer rates |
How Ties are Broken
This does not apply to Drugs. Hospital/Payer ties are broken by taking the hospital rate.
Sometimes we have both payer and hospital rates and they both have a canonical rate score of 4. Which one do we pick? Ties are broken by selecting the higher-likelihood rate. The "likelihood" is a statistic computed using our expectations for that code based on validated rates (payer/hospital reported similar rates).
Where can I see this likelihood score? It's in the validation score's decimals.
As an example, if the validation score is 6.85, the likelihood of randomly drawing the rate from the expected distribution is 85%.
We estimate the likelihood as the integral of the probability distribution function of a between . (i.e. difference of CDF at these two points)
and come from the observed distribution of validated rates for that billing code and provider type. We log transform the validated rates to reduce skew. In general this observed distribution is normal-ish enough. But we do exclude distributions that are too skewed even after a log transform. We also exclude distributions that are clearly multi-modal.
For more details, see accuracy scores v2